SEO之页面索引
- 1. 常见错误和解决方法
- 2. Hexo博客的SEO策略
《博客建站16 - SEO优化之网站收录》一文讲解了自己的网站如何被搜索引擎收录的方法。本文将讲解搜索引擎中“页面索引”相关的问题。
Google的搜索引擎站点管理平台Google Search Console中有一项页面索引(Page Indexing)的记录,会记录正常索引和异常索引的页面及其索引失败的原因。
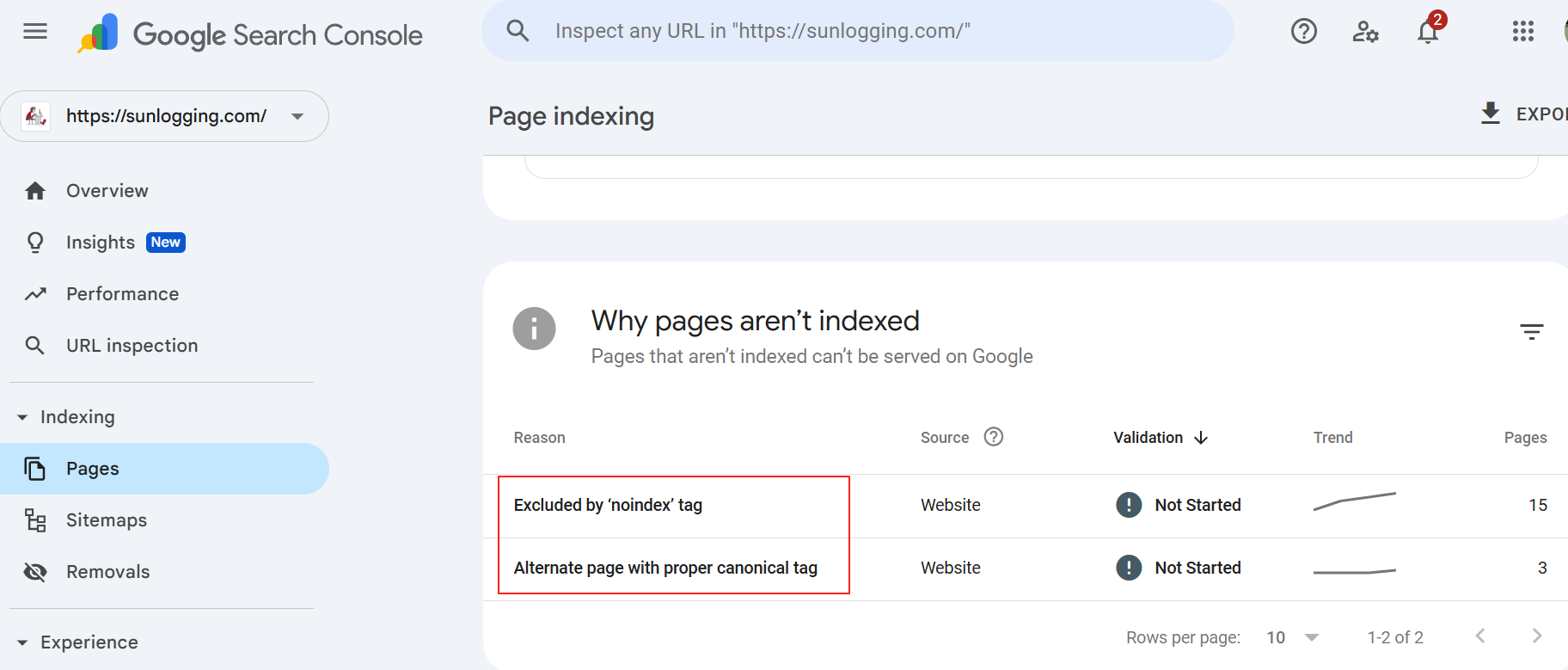
常见的索引失败的两个原因:
- Excluded by ‘noindex’ tag
- Alternate page with proper canonical tag
- Not found (404)
- Discovered - currently not indexed
- Crawled - currently not indexed
- Duplicate, Google chose different canonical than user
1. 常见错误和解决方法
1.1. Excluded by ‘noindex’ tag
1.1.1. 问题原因
网页HTML中含有<meta name="robots" content="noindex">标签,明确禁止Google索引该页面。
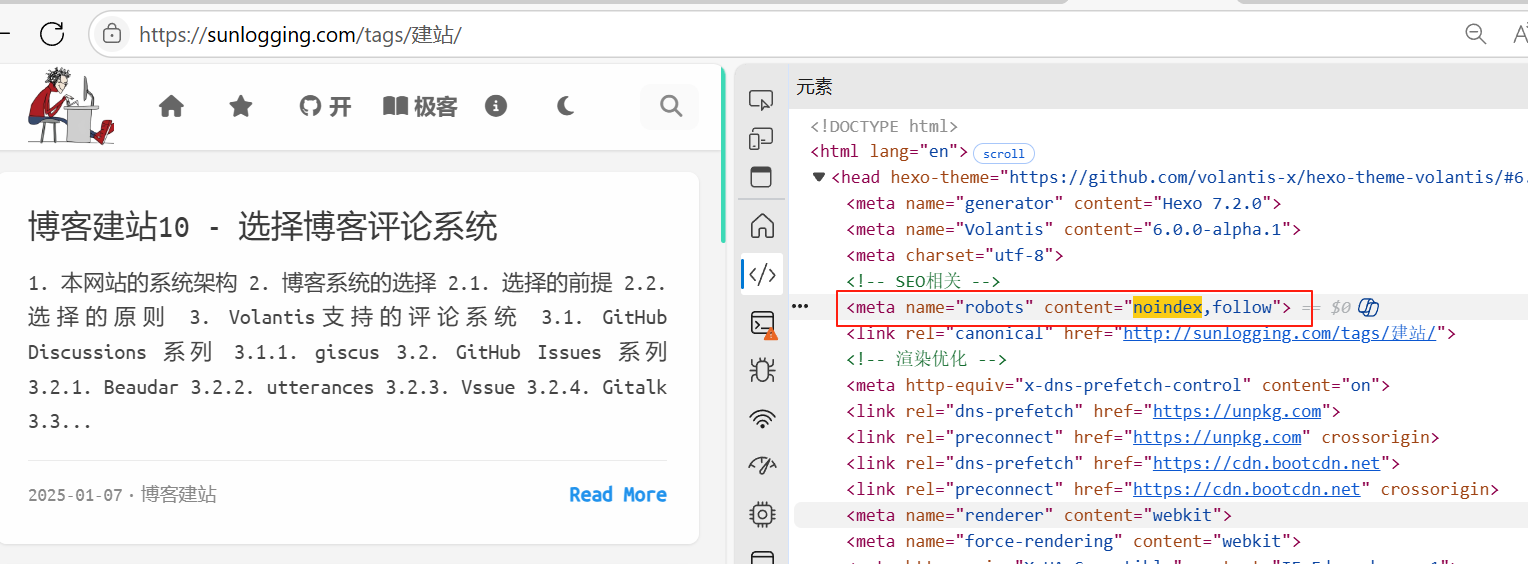
1.1.2. 原因分析
导致页面出现<meta name="robots" content="noindex">标签的原因可能如下:
1.2.1. 主题默认配置问题
- 多数 Hexo 主题(如 Volantis, NexT, Butterfly)默认给非文章页面(分类页/标签页/归档页)添加
noindex标签,避免重复内容被索引。 - 验证方法:检查页面 HTML 源码,搜索
noindex标签是否存在于/categories/、/tags/等路径页面。
1.2.2. 插件自动添加
- 插件如
hexo-generator-archive或hexo-generator-tag在生成页面时可能自动注入noindex。 - 典型场景:分类列表页、标签聚合页默认被标记为
noindex。
1.2.3. Front-matter 手动设置
-
在文章的 Markdown 头部(Front-matter)误添加了
noindex: true:---
title: 示例文章
noindex: true # 这会导致生成 noindex 标签
---
1.2.4. 模板文件逻辑错误
- 主题的模板文件(如
head.ejs)包含条件判断,当页面类型为特定值时自动添加noindex。
1.1.3. 解决办法
1.3.1. 方法 1:修改主题配置文件
-
打开主题的配置文件
_config.yml(位于themes/your-theme/目录) -
搜索
noindex或robots字段,修改为:# NexT 主题示例
noindex: false # 关闭全局 noindex
# Butterfly 主题示例
meta_robots:
noindex: false # 关闭自动 noindex
# volantis 主题示例
seo:
# 关键词优化(推荐开启)
use_tags_as_keywords: true # 自动用标签补充关键词,增强主题相关性
# 描述优化(强烈推荐开启)
use_excerpt_as_description: true # 用摘要作为meta描述,提高搜索结果点击率
# 机器人指令精细控制
robots:
# 首页策略
home_first_page: index,follow # 索引主首页(核心入口)
home_other_pages: noindex,follow # 禁止索引分页(如/page/2/)
# 归档页策略
archive: noindex,follow # 禁止索引(纯时间列表价值低)
# 分类页策略 - 选择性优化
category: noindex,follow # 默认禁止,特殊分类需单独处理
# 标签页策略 - 选择性优化
tag: noindex,follow # 默认禁止,高价值标签页需单独处理
1.3.2. 方法 2:修改页面模板文件
-
定位模板文件(通常在
themes/your-theme/layout/目录) -
检查以下文件是否包含
noindex逻辑:head.ejs/head.swig- 头部模板archive.ejs- 归档页模板category.ejs- 分类页模板tag.ejs- 标签页模板
-
删除或注释相关代码(示例):
<% if (is_home() || is_archive()) { %>
<!-- 删除或注释下一行 -->
<meta name="robots" content="noindex">
<% } %>
1.3.3. 方法 3:检查 Front-matter
-
排查文章/页面的 Markdown 文件头部
-
移除所有
noindex: true设置:---
title: 我的文章
- noindex: true # 删除此行
+ noindex: false # 或直接移除
---
1.3.4. 方法 4:覆盖默认插件行为
在 Hexo 根目录的 _config.yml 中添加:
# 禁止分类/标签页生成 noindex
tag_generator:
per_page: 0 # 设为0可禁用标签页
category_generator:
per_page: 0 # 禁用分类页
# 或直接关闭相关生成器
skip_render:
- categories/**/* # 跳过分类页生成
- tags/**/* # 跳过标签页生成
1.3.5. 方法 5:强制移除标签(终极方案)
在主题的脚本文件(如 scripts/robots-fix.js)中添加:
hexo.extend.filter.register('after_render:html', function(str) {
return str.replace(/<meta name="robots" content="noindex">/g, '');
});
这会全局移除所有
noindex标签(慎用,可能影响 SEO 策略)。
1.2. Alternate page with proper canonical tag
1.2.1. 问题原因
网页HTML中含有<link rel="canonical" href="...">标签,Google认为当前页面存在另一个更权威的版本,因此索引后者而非当前页。
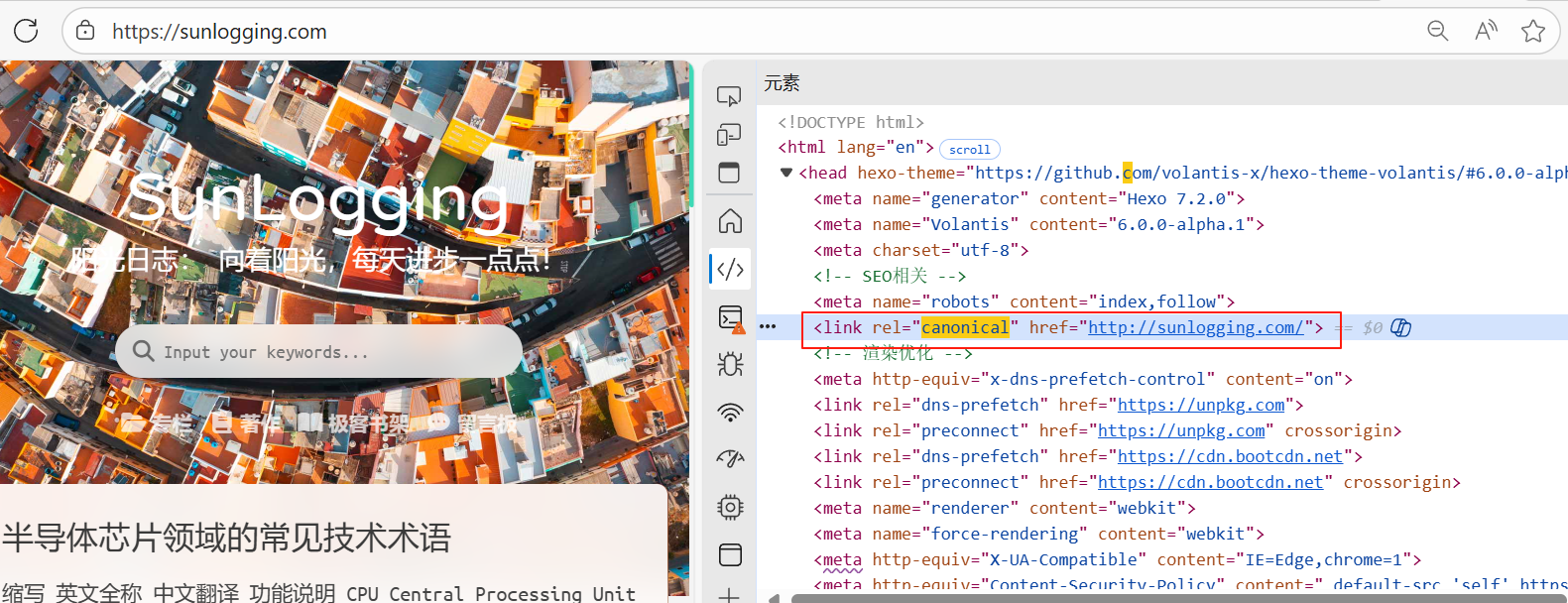
2.2. <link rel="canonical" href="..."> 的功能
-
声明权威版本
当多个 URL 显示相似内容时(如:example.com/post/和example.com/post/?ref=share),通过 canonical 标签指定哪个 URL 是"正宗版本"。 -
集中 SEO 权重
搜索引擎会将所有重复页面的权重(链接权重、点击信号等)集中传递到规范 URL,提升目标页面的排名能力。 -
防止索引分散
避免搜索引擎索引多个相似页面导致内容重复问题,保护网站不被降权。 -
跨域名规范
- 可指向不同域名的 URL(如将
blog.example.com指向www.example.com/blog),用于域名合并场景。 - HTTPS的页面指向了HTTP的页面(如将
https://sunlogging.com/指向http://sunlogging.com/)。
- 可指向不同域名的 URL(如将
1.2.2. 原因分析
Hexo 自动添加 canonical 标签是刻意设计的 SEO 保护机制,主要出现在以下页面:
| 页面类型 | 生成原因 | 典型示例 |
|---|---|---|
| 分页页面 | 防止 /page/2/ 与首页内容竞争 | <link rel="canonical" href="/"> |
| 分类/标签页 | 避免不同分类下的相同文章产生重复页面 | 文章同时出现在 /tag/A/ 和 /tag/B/ |
| 多语言版本 | 当使用 i18n 插件时,指向主语言版本 | 英文页指向中文原版 |
| AMP 页面 | AMP 页面必须指向标准版作为规范版本 | <link rel="canonical" href="原文章URL"> |
| 静态文件路径 | Hexo 的 pretty_urls 功能可能生成带 .html 和不带扩展名的双版本 | /about.html → /about/ |
1.2.3. 解决办法
2.2.3. 方法 1:全局禁用(不推荐)
在 Hexo 根目录的 _config.yml 中添加:
# 禁用所有 canonical 标签
canonical: false
⚠️ 警告:这将全面移除规范标签,可能导致重复内容问题
2.2.4. 方法 2:按页面类型精准控制(推荐)
在主题配置文件中修改(以 Volantis 主题为例):
# themes/volantis/_config.yml
seo:
canonical:
post: true # 文章页保留(必须)
page: true # 单页面保留
home: false # 关闭首页的规范标签
archive: false
category: false
tag: false
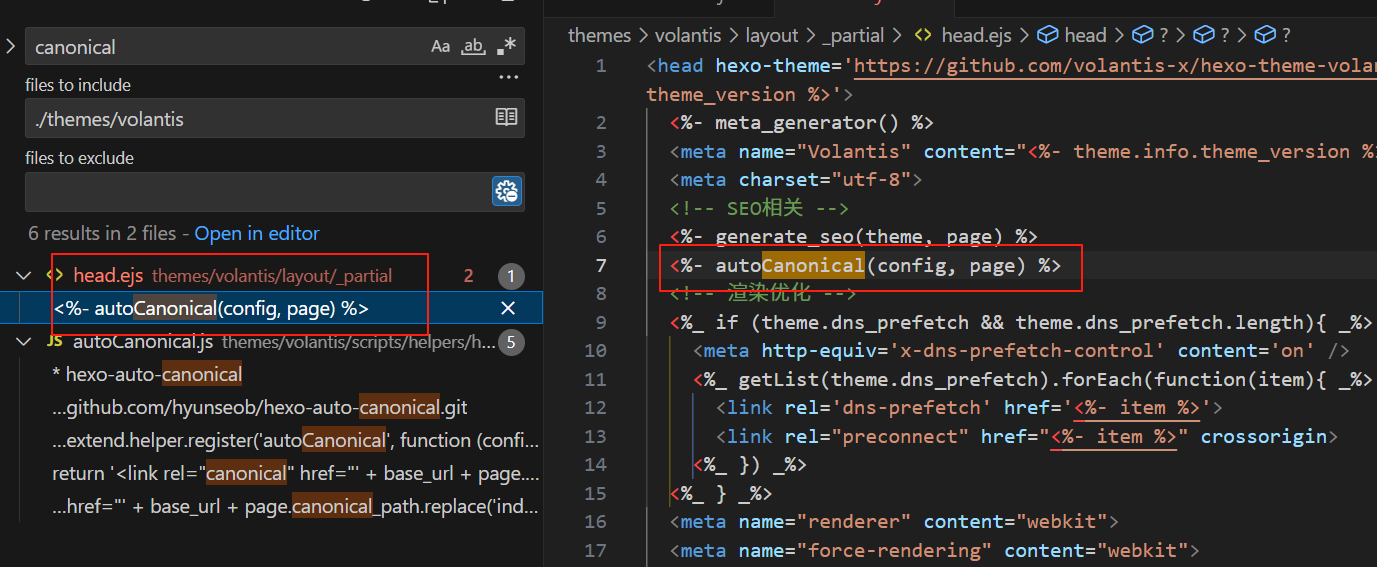
2.4.3. 方法 3:修改模板文件(终极方案)
-
定位模板文件(通常位于):
themes/volantis/layout/_partials/head.ejs -
查找并删除代码:
<% if (page.canonical) { %>
<link rel="canonical" href="<%= page.canonical %>">
<% } %>
2.4.4. 方法 4:条件过滤(智能保留)
在主题的脚本文件中添加(创建 scripts/canonical-filter.js):
hexo.extend.filter.register('after_generate', function(page) {
// 只保留文章页的 canonical
if (page.type !== 'post') {
page.canonical = null;
}
return page;
});
1.3. Not found (404)
1.3.1. 问题原因
Googlebot尝试抓取该URL,但服务器返回了“404 Not Found”状态码。表示该url在服务器上不存在,无法访问。
1.3.2. 原因分析
- 页面已被删除:该URL指向的页面已被删除。
- 网站结构更改:网站改版、目录结构调整后,旧的URL失效,没有设置正确的重定向。
- URL错误:如拼写错误、中文URI编码错误等。
1.3.3. 解决办法
-
页面已被删除: 向搜索引擎提交死链,主动告知搜索引擎该链接已经失效。
-
网站结构更改:
- 检查并修复网站内部(导航、内容链接、图片链接等)指向该404页面的错误链接,将它们指向正确的URL。
- 设置301重定向,将失效的URL 301重定向到最相关、内容最相似的新页面。
-
URL错误: 查找导致URL错误的根本原因,并修复错误。
- 举例:我的网站的分类页面(
https://sunlogging.com/categories/XXX)如果包含中文,会出现URI编码错误,导致URL无法访问。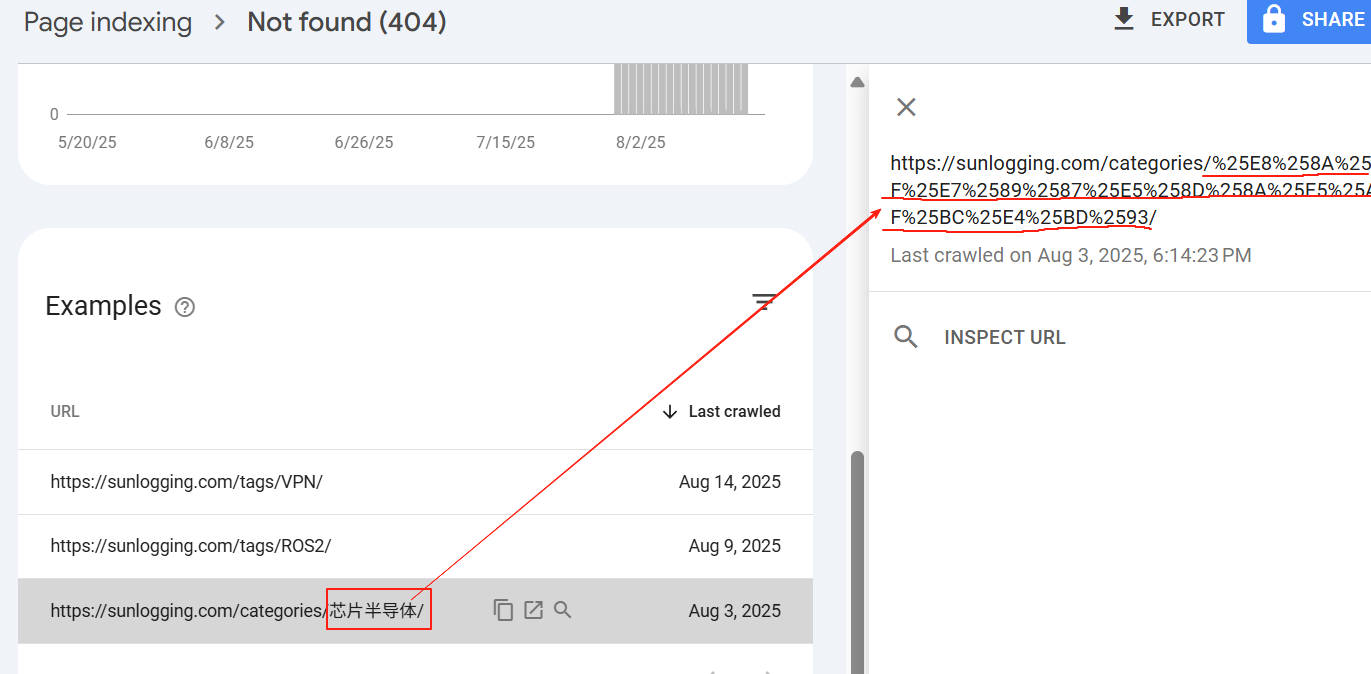
- 分析原因发现是生成的站点地图(
https://sunlogging.com/category-sitemap.xml)的URL错误,包含中文的URL出现了重复编码。 - 我的站点地图是通过
hexo-generator-seo-friendly-sitemap插件生成的,找到node_modules/hexo-generator-seo-friendly-sitemap/views/category-sitemap.ejs文件,将<loc><%- encodeURLAndEscape(category.permalink) %></loc>修改成<loc><%- category.permalink %></loc>。 - 执行
hexo clean && hexo s重新生成页面,发现新的站点地图的URL就正确了。
- 举例:我的网站的分类页面(
1.4. Discovered - currently not indexed
1.4.1. 问题描述
Googlebot通过某种方式(如其他页面的链接、Sitemap)发现了该URL,但尚未尝试抓取它,因此更谈不上索引。
1.4.2. 问题原因
- 爬虫预算限制: 网站规模过大、结构复杂或存在大量低价值页面,导致Googlebot无法在有限资源(爬虫预算)内抓取所有已发现的URL。优先级低的页面(如深层分页、标签页、过滤页、旧内容)常被搁置。
- 内部链接结构不佳: 页面缺乏来自高权威页面(如主页、重要分类页)的强有力内部链接,导致Googlebot难以发现或认为其重要性较低。
- Sitemap问题: Sitemap包含过多URL(尤其低质量URL),或者Sitemap本身未被有效处理。
- 新页面或更新页面: 页面刚被发现,Googlebot还未安排抓取(需要时间)。
- 网站整体抓取障碍: 网站存在大量技术问题(如服务器慢、大量404/5xx错误)消耗了爬虫预算,导致新页面抓取被延迟。
1.4.3. 原因分析
这表明页面没有被抓取的根本障碍(否则会报抓取错误),而是Googlebot在资源分配上暂时没有选择抓取它。核心在于页面的可发现性和在Google眼中的相对优先级/价值不够高。
1.4.4. 解决办法
- 提升页面优先级:
- 优化内部链接: 从网站重要页面(主页、高流量分类页、相关高权重内容页)添加指向该页面的链接。使用描述性锚文本。
- 突出显示: 将页面放在更显眼的导航位置。
- 优化Sitemap:
- 精简Sitemap: 只包含真正重要、希望被索引的URL。移除低价值页面(如分页、过滤页、标签页、作者页,除非它们有独特价值)。
- 优先级和更新频率: 合理设置
sitemap.xml中的<priority>和<changefreq>(虽然Google主要用作参考),标记重要页面。 - 提交Sitemap: 确保在GSC中提交了最新的Sitemap。
- 提高网站整体健康度:
- 减少爬行浪费: 解决大量404、5xx错误,修复重定向链,优化robots.txt规则(避免不必要地屏蔽)。
- 提升网站速度: 服务器响应快、页面加载快,能让Googlebot更高效抓取。
- 优化网站结构: 扁平化结构,减少点击深度。
- 创建高质量内容: 确保页面内容独特、有价值、信息丰富,值得被索引。这本身就能提高Google抓取的意愿。
- 耐心等待: 对于新页面或更新,给予Google时间(几天到几周)去发现和抓取。
1.5. Crawled - currently not indexed
1.5.1. 问题描述
Googlebot已成功抓取(获取了页面HTML内容),但决定不将其加入索引。
1.5.2. 问题原因
这是最复杂的情况,原因多样,核心是Google认为索引该页面对搜索用户价值不大或存在问题:
- *内容质量问题:
- 内容单薄/价值低: 内容过短、缺乏深度、信息重复(站内或站外)、大量抄袭、可读性差、用户价值低。
- 自动化/AI生成低质内容: 内容由工具大量生成,缺乏人工编辑、原创性和深度。
- 过度优化/垃圾内容: 关键词堆砌、隐藏文本、门页等黑帽SEO手法。
- *内容新鲜度/时效性问题: 内容已过时且未被更新,Google认为不再相关。
- 重复内容问题: 页面内容与站内其他页面高度相似,且未被正确使用
rel="canonical"或noindex处理,Google选择索引其中一个版本而忽略此页。 - *技术性原因:
noindex指令存在: 页面HTML头或HTTP响应头中包含noindex元标签或指令。- 被robots.txt阻止索引: 虽然抓取成功(因为robots.txt只控制索引,不控制抓取),但robots.txt规则阻止了该URL的索引(如使用了
Disallow:但未配合noindex,这是常见误解)。 - 登录/付费墙限制: 页面内容需要登录或付费才能查看完整内容,而Googlebot无法访问。
- 抓取渲染问题: Googlebot在渲染页面(执行JS)时遇到问题,导致看到的内容与用户不同或为空。
- 服务器问题: 抓取时服务器返回了非200状态码(如5xx错误),但报告可能延迟或状态码短暂异常。
- 资源限制: 类似“Discovered”的原因,在抓取后评估阶段,Google可能因资源限制优先索引更重要的页面。
- 新页面/更新页面: 页面刚被抓取,索引决策需要时间(通常比抓取延迟更短)。
1.5.3. 原因分析
- Google已看到内容但主动拒绝索引,这表明页面存在实质性障碍或价值不足。需要深入分析内容质量、技术设置和重复性。这是最需要仔细排查的一类问题。
1.5.4. 解决办法
- 检查技术指令:
- 使用GSC的URL检查工具或查看页面源代码,确认没有意外的
<meta name="robots" content="noindex">标签。 - 检查页面HTTP响应头(可通过浏览器开发者工具Network标签或在线工具查看),确认没有
X-Robots-Tag: noindex指令。 - 检查
robots.txt文件,确保没有规则阻止该URL的抓取且你希望它被索引。记住:robots.txt的Disallow仅阻止抓取,阻止索引需要noindex。如果URL被Disallow但又可公开访问,Google可能发现它但无法抓取(报抓取错误)或抓取后因Disallow而不索引(报此错误)。确保两者意图一致。
- 使用GSC的URL检查工具或查看页面源代码,确认没有意外的
- 彻底评估内容质量:
- 提升价值: 内容是否独特、深入、全面、解决了用户问题?与排名靠前的页面相比如何?大幅扩充、更新、提升原创性和专业性。
- 解决重复: 如果与其他页面高度相似,使用
rel="canonical"明确指定权威版本,或对低价值重复页面使用noindex。 - 避免低质/自动化: 确保内容是人工创作、编辑、有价值的。避免纯粹为SEO生成大量薄内容。
- 检查渲染: 使用GSC的URL检查工具中的“测试实际页面”功能,查看Google渲染后的页面是否正常、内容是否完整显示。
- 检查可访问性: 确保页面无需登录即可被Googlebot访问到完整内容。移除不必要的付费墙或登录要求,或使用合适的标记(如结构化数据)告知Google如何处理受限内容。
- 提升页面信号:
- 加强内部链接: 从权威页面链接过来,传递权重。
- 获取外部链接: 高质量外链是重要的信任和重要性信号。
- 请求重新索引: 在修复问题后(尤其是技术指令或内容大幅更新后),使用GSC的URL检查工具提交该URL请求重新索引。
- 耐心等待: 修复后给予Google时间重新评估。
1.6. Duplicate, Google chose different canonical than user
1.6.1. 问题描述
存在多个内容高度相似的页面(重复页面)。网站管理员通过rel="canonical"标签、sitemap设置或参数处理工具指定了一个首选规范版本(User - declared canonical),但Google在评估后选择了另一个不同的页面作为它认为的规范版本(Google - selected canonical)进行索引。
1.6.2. 问题原因
Google选择不同规范页的核心原因是它认为其选择比用户声明的版本更符合“最佳规范页面”的标准:
规范信号冲突/弱
- 用户声明不一致:不同页面指向不同的规范版本(内部链接混乱),或者sitemap、
rel="canonical"、参数处理工具的设置相互冲突。 rel="canonical"指向错误:声明的规范页本身是重复页、低质页、被屏蔽页(如noindex或disallow)、或甚至是404页面。- 规范页信号弱:用户声明的规范页面缺乏强有力的信号证明自己是“最佳”版本(如缺少外链、内部链接少、在sitemap中未标记为重要)。
Google选择的页面更“强”
- 更多/更高质量链接:Google选择的页面可能获得了更多或更高质量的内部链接和外部链接。
- 更易访问:Google选择的页面可能没有被robots.txt阻止、没有
noindex、加载更快或更稳定。 - 内容更完整/更新:Google认为它选择的页面内容更完整、更新更及时或布局更好(即使内容相似)。
- URL结构更友好:Google可能偏好更简洁、包含关键字的静态URL,而非包含冗长参数的动态URL。
- 历史原因:Google可能先发现并索引了它选择的那个版本。
1.6.3. 原因分析
这表示Google不完全信任或不认同用户设置的规范信号。虽然索引通常没问题(Google只索引一个版本),但隐患在于:
- 索引了不想索引的页面:你希望推广的规范版本可能没被索引,而被索引的是你想隐藏的版本(如带参数的URL)。
- 链接权重分散:指向不同重复版本的链接权重可能没有很好地集中到你想推广的规范页上。
- 潜在索引问题:如果Google选择的页面后来被屏蔽(如
noindex),可能导致整个内容从索引中消失。
1.6.4. 解决办法
- 理解Google的选择:在GSC覆盖率报告的详情中查看Google选择了哪个页面作为规范页。分析为什么Google认为那个页面更合适。
- 统一并强化规范信号:
- 一致性:确保所有重复页面(包括Google选中的那个)的
rel="canonical"标签都指向同一个、你真正希望作为规范的URL。这是最重要的信号。 - Sitemap:只在Sitemap中包含规范URL。如果包含非规范页,确保它们标记了正确的
rel="canonical"。 - 内部链接:尽量在内部链接结构中直接使用和指向规范URL。
- 一致性:确保所有重复页面(包括Google选中的那个)的
- 优化规范页面:
- 确保规范页最强:让你指定的规范页成为最强版本:确保它没有被
noindex或disallow,提升其内容质量和完整性,尽可能多地让高质量内部链接指向它,努力为其获取外部链接。 - 移除或处理非规范页:
noindex:如果某些重复页(如带参数的URL、打印页)完全没有独立存在价值,且你不想它们被索引,直接添加noindex标签。同时确保它们仍能被爬取(不被robots.txt阻止),以便Google看到noindex指令。- 301重定向:对于明显是重复且不需要独立访问的页面(如
?sessionid = 123这类URL),最佳实践是301重定向到规范URL。这最有效地传递权重并消除混淆。 - 参数处理:在GSC的URL参数工具中设置参数处理规则,告知Google哪些参数不影响内容(可忽略),哪些会改变内容(需单独索引),哪些会产生重复(应规范到主URL)。这需要谨慎配置。
- 确保规范页最强:让你指定的规范页成为最强版本:确保它没有被
- 修复技术问题:确保你指定的规范页可被抓取和索引(200状态码,无
noindex,未被robots.txt阻止),且加载正常。 - 重新提交与监控:修复后,使用URL检查工具分别检查几个重复页面和你指定的规范页,请求索引。监控覆盖率报告,看Google是否开始接受你的规范声明。
2. Hexo博客的SEO策略
2.1. 为什么Hexo搭建的博客默认会为 分类页/标签页/归档页 添加noindex 标签?
2.1.1. 防止重复内容问题(Duplicate Content)
分类页和标签页本质上是聚合页面,通过动态调用关联文章生成列表。若允许索引,会出现以下问题:
- 内容重复性高:同一篇文章可能出现在多个标签页中,导致内容高度相似;
- 与文章页竞争:当用户搜索文章主题时,搜索引擎可能返回标签页而非原始文章页,分散权重。
2.1.2. 避免索引低价值页面
分类/标签页通常只包含文章标题、摘要等片段信息,内容深度不足,用户更倾向于点击具体文章。索引此类页面会:
- 浪费搜索引擎抓取配额(Crawl Budget);
- 拉低网站整体内容质量评分。
2.1.3. 控制权重分配(Link Equity)
若分类/标签页可被索引,内部链接结构会变得复杂:
- 文章页的权重可能被分散到多个聚合页;
- 关键内容页(如教程、产品页)获得的权重下降。
2.1.4. 总结
| 场景 | 添加 noindex 的收益 | 不添加 noindex 的风险 |
|---|---|---|
| 内容重复性 | ✅ 避免多页面内容相似导致权重稀释 | ❌ 文章页与标签页竞争排名,双方排名均下降 |
| 抓取效率 | ✅ 节省抓取配额,优先索引高质量文章页 | ❌ 搜索引擎抓取大量低价值页,忽略新文章 |
| 用户体验 | ✅ 用户直接定位到文章页,减少无效跳转 | ❌ 搜索结果中出现空列表页,用户跳出率升高 |
短期看,noindex 可能减少索引量,但长期看,它提升了网站内容质量和权重集中度,属于战略性 SEO 优化手段。对SEO的影响,总的来说是利大于弊。