CUDA代码编译流程
1. CUDA Toolkit 概述
1.1. 什么是CUDA Toolkit?
CUDA Toolkit是NVIDIA提供的并行计算平台和编程模型,它包含:
- NVCC编译器:CUDA C/C++编译器
- CUDA运行时库:提供GPU功能访问接口
- 开发工具:调试器、性能分析器等
- 数学库:cuBLAS、cuFFT、cuRAND等
- 头文件和文档
1.2. 核心组件
# 主要组件路径(Linux示例)
/usr/local/cuda/
├── bin/ # NVCC编译器和其他工具
├── include/ # CUDA头文件
├── lib64/ # CUDA库文件
└── samples/ # 示例代码
2. CUDA程序编译流程
2.1. 完整编译过程
CUDA程序的编译是一个多阶段过程,涉及主机代码和设备代码的分离处理:
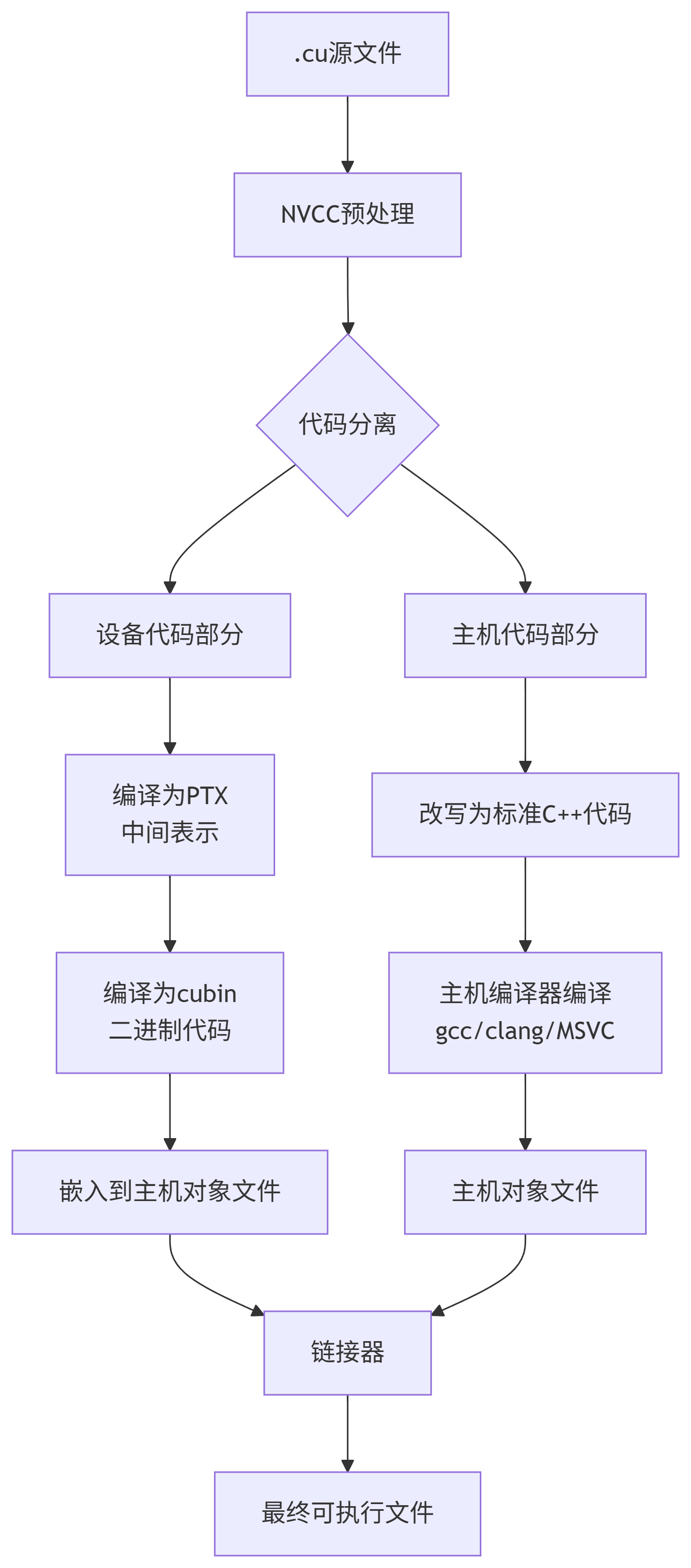
2.2. 编译示例
直接编译:
# 1. 编译成可执行文件./hello
nvcc hello.cu -o hello
# 2. 运行可执行文件./hello
./hello
Hello World from CPU!
Hello World from GPU!
Hello World from GPU!
分步编译:
# 1. 将CUDA源码编译成设备中间代码(PTX)
nvcc -ptx hello.cu -o hello_device.ptx
# 2. 将PTX中间代码编译为cubin二进制文件
nvcc -cubin hello_device.ptx -o hello_device.o
# 3. 将CUDA源码编译成主机标准代码
nvcc --cuda -x cu -dc hello.cu -o hello_host.cpp
# 4. 将主机代码编译为主机对象文件
g++ -c -I/usr/local/cuda/include hello_host.cpp -o hello_host.o
# 5. 链接生成最终可执行文件
g++ hello_host.o hello_device.o -o hello -L/usr/local/cuda/lib64 -lcudart
# 6. 运行可执行文件
./hello
3. NVCC编译原理详解
3.1. 代码分离机制
NVCC通过以下方式识别和处理代码:
// 设备函数 - 在GPU上执行
__device__ float device_function() {
return 1.0f;
}
// 全局函数(内核) - 从CPU调用,在GPU执行
__global__ void kernel_function(float* data) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
data[idx] = device_function();
}
// 主机函数 - 在CPU上执行
void host_function() {
float* d_data;
cudaMalloc(&d_data, 100 * sizeof(float));
kernel_function<<<10, 10>>>(d_data); // 启动内核
cudaFree(d_data);
}
3.2. PTX(Parallel Thread Execution)中间表示
PTX是CUDA的虚拟指令集架构,具有重要作用:
- 跨平台兼容性:PTX代码可以在不同架构的GPU上运行
- 即时编译:GPU驱动程序在运行时将PTX编译为特定架构的机器代码
- 优化目标:NVCC将CUDA C++代码编译为PTX,再进行优化
# 生成PTX文件
nvcc -ptx my_kernel.cu -o my_kernel.ptx
3.3. 编译阶段详解
3.3.1. 阶段1:预处理和代码分离
# 查看预处理结果
nvcc -E my_program.cu -o my_program.preprocessed
NVCC执行:
- 宏展开和头文件包含
- 识别
__global__、__device__、__host__限定符 - 分离主机代码和设备代码
3.3.2. 阶段2:设备代码编译
# 保留所有中间文件查看编译过程
nvcc --keep -arch=sm_75 my_program.cu
生成的文件:
my_program.cpp1.ii:预处理后的主机代码my_program.cpp4.ii:预处理后的设备代码my_program.ptx:PTX中间代码my_program.sm_75.cubin:特定架构的二进制代码
3.3.3. 阶段3:主机代码编译
设备代码被嵌入到主机对象文件中,主机代码被改写为:
// NVCC生成的主机代码包装
void __cudaRegisterFunction(void** fatbin, const char* name) {
// 注册设备函数
}
extern "C" void kernel_wrapper(float* data) {
// 设置内核参数、启动配置等
kernel_function<<<10, 10>>>(data);
}
3.3.4. 阶段4:链接
将所有组件链接为最终可执行文件,包括:
- 主机对象文件
- 设备代码(嵌入在fatbinary中)
- CUDA运行时库
4. Fatbinary和多架构支持
4.1. 多版本代码生成
NVCC可以生成包含多个架构版本的fatbinary:
# 生成支持多种架构的代码
nvcc -gencode arch=compute_70,code=sm_70 \
-gencode arch=compute_75,code=sm_75 \
-gencode arch=compute_80,code=sm_80 \
my_program.cu -o my_program
4.2. 运行时架构选择
GPU驱动程序会自动选择最适合当前GPU的代码版本:
- 优先选择精确匹配的cubin二进制
- 如果没有匹配的二进制,选择PTX代码进行JIT编译
- 确保程序在不同代GPU上的兼容性
5. 编译优化技术
5.1. 优化级别
# 不同优化级别
nvcc -O0 my_program.cu # 无优化,用于调试
nvcc -O1 my_program.cu # 基本优化
nvcc -O2 my_program.cu # 默认优化级别
nvcc -O3 my_program.cu # 激进优化
5.2. 寄存器使用控制
# 限制寄存器使用以提高 occupancy
nvcc --maxrregcount=32 my_program.cu -o my_program
5.3. 调试信息
# 生成调试信息
nvcc -G -g my_program.cu -o my_program_debug # 设备调试
nvcc -lineinfo my_program.cu -o my_program # 行号信息(Nsight兼容)
6. 实际编译示例
6.1. 完整项目编译
# Makefile示例
CC = nvcc
CFLAGS = -arch=sm_75 -O3 --compiler-options -Wall
LDFLAGS = -lcudart -lcurand
TARGET = my_app
SOURCES = main.cu kernel.cu utils.cu
OBJECTS = $(SOURCES:.cu=.o)
$(TARGET): $(OBJECTS)
$(CC) $(CFLAGS) -o $@ $^ $(LDFLAGS)
%.o: %.cu
$(CC) $(CFLAGS) -c $< -o $@
clean:
rm -f $(TARGET) $(OBJECTS)
6.2. 编译过程验证
# 查看详细的编译过程
nvcc -v -arch=sm_75 my_program.cu -o my_program
# 检查生成的可执行文件信息
cuobjdump my_program # 查看嵌入的设备代码
7. 总结
CUDA编译流程的核心特点:
- 分离编译:主机代码和设备代码分别处理
- 中间表示:使用PTX实现跨架构兼容
- Fatbinary:支持多架构版本共存
- 运行时集成:CUDA运行时负责设备管理和内核启动
- 工具链集成:与主流C++编译器无缝协作
理解CUDA编译原理对于:
- 优化程序性能
- 调试复杂问题
- 实现跨平台兼容
- 深入理解CUDA编程模型
都非常重要。掌握这些知识可以帮助开发者编写更高效、更稳定的CUDA应用程序。