附录B Nvidia各个型号GPU的架构和内存模型
NVIDIA 的 GPU 架构发展是一部从图形处理迈向通用计算,并最终引领人工智能浪潮的技术史诗。下面我将为你梳理其发展历程、架构设计细节以及各代架构的演变。
NVIDIA 的 GPU 架构发展是一部从图形处理迈向通用计算,并最终引领人工智能浪潮的技术史诗。其架构设计始终围绕着并行计算效率这一核心,通过不断演进的 SM(Streaming Multiprocessor,流式多处理器) 结构、专用计算单元(如 Tensor Core、RT Core)和多层次内存系统,来满足日益增长的计算需求。
1. NVIDIA GPU 架构发展历程概览
1.1. 发展历程
以下是 NVIDIA 近年来主要 GPU 架构的发布时间、核心特性及代表性产品,帮助你快速了解其演进脉络:
| 架构名称 | 发布时间 | 核心创新与特点 | 代表产品 | 工艺制程 | 关键计算特性 |
|---|---|---|---|---|---|
| Tesla | 2006年 | 引入统一着色器架构与CUDA,开启GPU通用计算时代;全面支持DirectX 10 | GeForce 8800 Ultra | 90nm | 128个流处理器(CUDA核心前身) |
| Fermi | 2010年 | 首次支持ECC显存保护,引入双精度浮点运算,优化科学计算性能 | GeForce GTX 480 | - | 480个CUDA核心 |
| Kepler | 2012年 | 引入GPU Boost动态超频技术,优化能效比 | GeForce GTX 680 | - | 1536个CUDA核心 |
| Maxwell | 2014年 | 能效优化,SM单元设计实现更高能效 | GeForce GTX 980 | - | - |
| Pascal | 2016年 | 专为深度学习设计,支持所有主流深度学习计算框架;引入NVLink互联 | GeForce GTX 1080 Ti | 16nm | 支持混合精度计算(FP16) |
| Volta | 2017年 | 首次引入Tensor Core,加速矩阵运算;大幅提升深度学习训练与推理速度 | Tesla V100 | - | 内置张量核心(Tensor Core) |
| Turing | 2018年 | 首款集成RT Core(光线追踪核心)与Tensor Core(AI核心),支持DLSS(深度学习超采样);实现实时光线追踪 | GeForce RTX 2080 Ti | 12nm | 4352个CUDA核心 |
| Ampere | 2020年 | 第二代RT Core与第三代Tensor Core;DLSS 3实现帧生成技术,AI算力提升2倍 | GeForce RTX 3090 | 8nm | 10496个CUDA核心;支持TF32, FP64精度;稀疏计算 |
| Ada Lovelace | 2022年 | 第四代Tensor Core,支持FP8精度计算;第三代RT Core;引入着色器执行重排序(SER)技术和DLSS 3技术 | GeForce RTX 4090 | - | FP8精度计算 |
| Hopper | 2022年 | 面向AI和HPC市场;采用第三代张量核心和编程模型(如CUDA图) | H100 | 4nm (N4) | 支持FP8精度 |
| Blackwell | 2024年 | 第四代Tensor Core;第二代Transformer引擎;支持FP4精度、NVLink 5.0;AI驱动渲染革命;DLSS 4 | B100, RTX 5090 D v2 | 台积电4NP | 支持FP4精度;AI算力大幅提升 |
| Rubin (预计) | 2026年 | 将搭配下一代HBM4高带宽内存;与Vera CPU组成新一代超级芯片 | R100 (预计) | 台积电3nm | 预计AI算力进一步提升 |
1.2. 架构参数和文档
| 架构名称 | 发布时间 | 计算能力 | PCIe | NVLink | Tensor Cores | RT Cores | 架构文档 |
|---|---|---|---|---|---|---|---|
| Tesla | 2006年 | 1.x | 1.0 | - | - | - | 架构(英文) |
| Fermi | 2010年 | 2.x | 2.0 | - | - | - | Fermi架构(英文) |
| Kepler | 2012年 | 3.x | 3.0 | - | - | - | Kepler-GK110/210架构(英文) |
| Maxwell | 2014年 | 5.x | 3.0 | - | - | - | 架构(英文) |
| Pascal | 2016年 | 6.x | 3.0 | 1.0 (40 GB/s) | - | - | Pascal-TeslaP100架构(英文) |
| Volta | 2017年 | 7.x | 3.0 | 2.0 (300 GB/s) | 第一代 | - | Volta-TeslaV100架构(英文) |
| Turing | 2018年 | 7.5 | 3.0 | - | 第二代 | 第一代 | Turing架构(英文) |
| Ampere | 2020年 | 8.x | 4.0 | 3.0 (600 GB/s) | 第三代 | 第二代 | Ampere-A100架构(英文) |
| Ada Lovelace | 2022年 | 8.9 | 4.0 | 3.0 (600 GB/s) | 第四代 | 第三代 | ADA架构(英文) |
| Hopper | 2022年 | 9.x | 5.0 | 4.0 (900 GB/s) | 第四代 | - | Hopper-H100架构(英文) Hopper-H100架构(中文) (注3) |
| Blackwell | 2024年 | 12.x | 5.0 | 5.0 (1.8 TB/s) | 第五代 | 第四代 | Blackwell架构(英文) |
说明:
- Tesla架构是NVIDIA首个通用并行计算(GPGPU)架构,也是从这个架构开始引入的CUDA,之前的GPU基本上只专用于图形渲染加速。注意:
Tesla架构与此后的Tesla系列计算卡不同,后者是用于高性能计算和科学计算的显卡系列。 - Hopper架构主要面向数据中心和 AI 计算,其核心创新在于 Tensor Core 和 Transformer 引擎的极致优化,而非面向消费级游戏的RT Core,因此Hopper的显卡没有RT Core。
- Volta架构开始引入第一代Tensor Core,Turing架构开始引入第一代RT Core。
1.3. 参考文档
2. NVIDIA GPU 架构设计详解
2.1. GPU核心阵列
现代NVIDIA GPU(特别是从Fermi架构开始)已经演变为一个高度并行的、集成众多专用处理单元的复杂芯片,而不仅仅是简单的图形处理器。
其核心设计理念是:一个由大量通用计算核心(CUDA Cores)组成的大规模并行阵列,并辅以多种专用处理器(如Tensor Core, RT Core)来高效处理特定的重型工作负载。
2.1.1. GPC/TPC/SM之间的关系
| 层级 | 名称 | 功能 | 说明 |
|---|---|---|---|
| GPU | Graphics Processing Unit,图形处理单元 | 一个完整的GPU显卡 | 一个GPU会有多个GPC |
| GPC | Graphics Processing Cluster,图形处理集群 | 是GPU芯片内部最大的可独立运作的模块化分区 | 一个GPC会有多个TPC |
| TPC | Texture Processing Cluster,纹理处理集群 | 是一个介于GPC和SM之间的中间管理层或组织单元 | 一个TPC会有多个SM |
| SM | Streaming Multiprocessor,流式多处理器 | 是NVIDIA GPU最核心、最基础的计算单元,是所有计算实际发生的地方,是执行CUDA线程的最终硬件单元。 | 一个SM会有一到多个不同种类的核心(如CUDA Core、Tensor Core、RT Core) |
说明: 他们之间的是层级的包含关系:GPU → GPC → TPC → SM → Core(CUDA, Tensor, RT)。
2.1.2. 产品举例
Hopper架构GH100 GPU
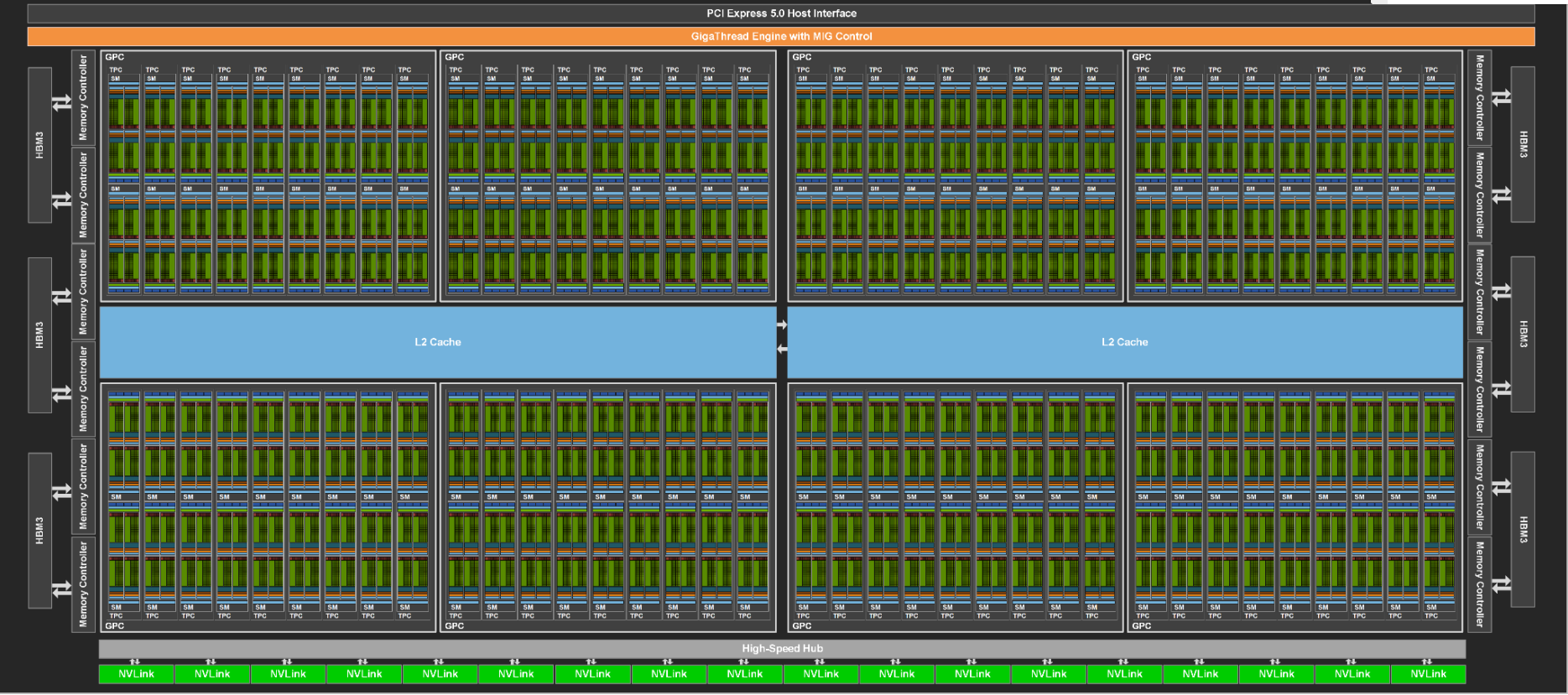 图1:完整的GH100 GPU核心
图1:完整的GH100 GPU核心
- 8个GPC、9个TPC/GPC、2个SM/TPC。
- 每个完整GPU内含8个GPC,72个TPC(89),144个SM(89*2)。
- 6 个 HBM3 或 HBM2e 堆栈、12 个 512 位内存控制器
- 60MB 二级缓存
- 第四代 NVLink 和 PCIe 5.0
注意: 实际销售的产品可能并非完整版本,可能会有阉割版。请识别自己对应的型号,具体型号参数如下。

Ampere架构A100 GPU
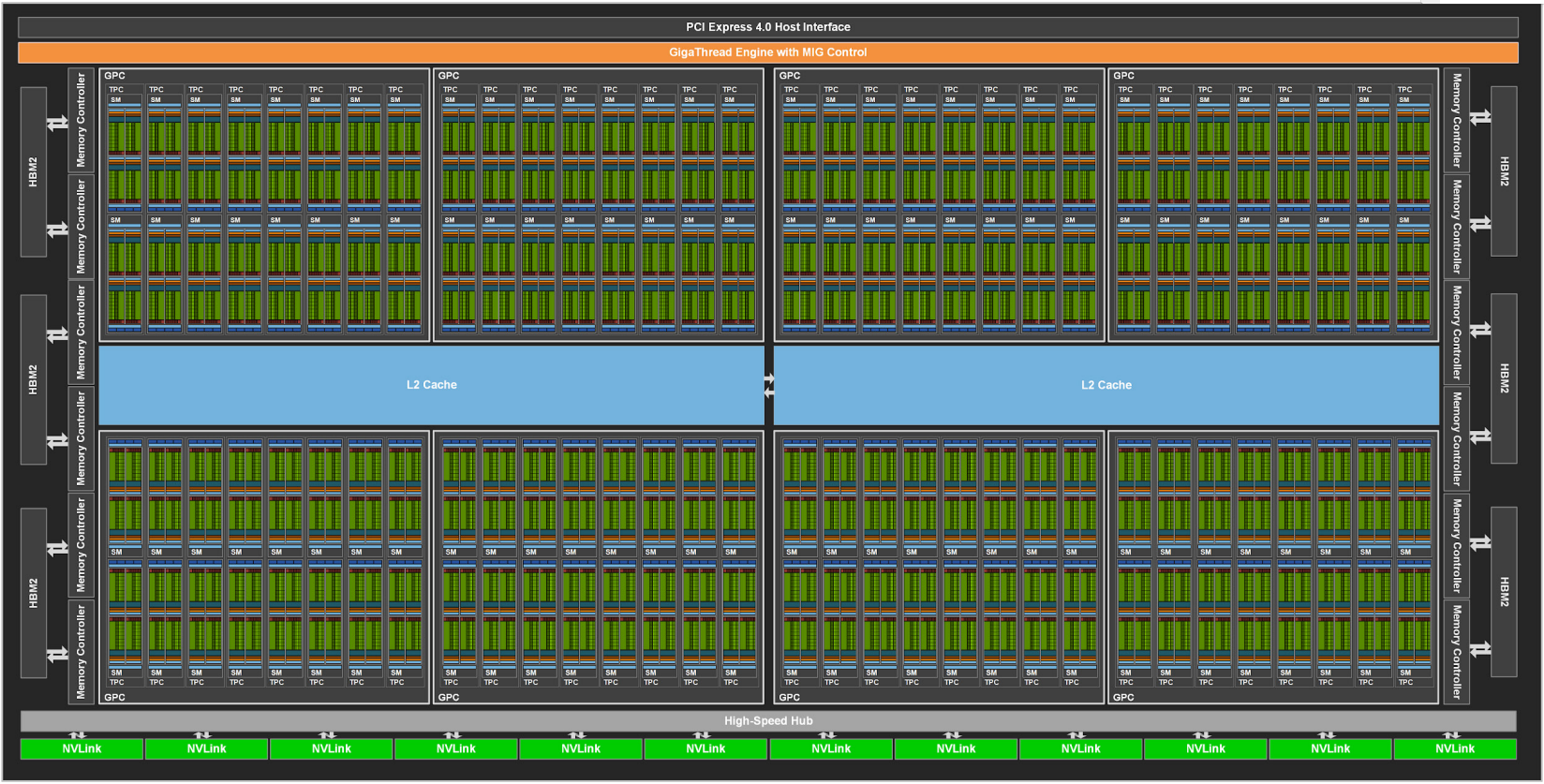 图2:完整的A100 GPU核心
图2:完整的A100 GPU核心
- 8个GPC、8个TPC/GPC、2个SM/TPC。
- 每个完整GPU内含8个GPC,64个TPC(88),128个SM(88*2)。但是
A100 Tensor Core版实际上只有108个SM,说明他其实对SM是有阉割的(比完整版少了20个SM)。
注意: 实际销售的产品可能并非完整版本,可能会有阉割版。请识别自己对应的型号,具体型号参数如下。

2.2. SM结构说明
2.2.1. SM的组成
SM(Streaming Multiprocessor,流式多处理器)是NVIDIA GPU最核心、最基础的计算单元,是所有计算实际发生的地方,是执行CUDA线程的最终硬件单元。
- CUDA Cores(CUDA 核心):用于执行单精度浮点(FP32)和整数(INT32)运算的基本单元。其数量是衡量 GPU 通用计算能力的关键指标之一。
- Tensor Cores(张量核心):专为深度学习中的矩阵乘加运算(MMA)设计的专用硬件单元,支持多种精度(如 FP16, BF16, TF32, FP8, FP4),能极大加速 AI 训练和推理。
- RT Cores(光线追踪核心):专门用于加速光线与三角形求交等光线追踪计算,是实现实时光线追踪的关键。
- 特殊功能单元(SFU):执行一些特殊的数学运算。
- 寄存器文件(Register File):为每个线程提供高速的私有存储空间。
- 共享内存(Shared Memory) / L1 缓存:一个由 SM 内所有线程共享的高速、可编程的片上内存池,用于实现线程块内的数据交换和重用,对性能优化至关重要。
2.2.2. 产品举例
Hopper架构GH100的SM架构
 图3:GH100流式多处理器(SM)
图3:GH100流式多处理器(SM)
- 每个 SM 内含 128(324) 个 FP32 CUDA Core 核心、每个完整 GPU 内含 18432(128144) 个 FP32 CUDA Core 核心
- 每个 SM 内含 4 个第四代 Tensor Core 核心、每个完整 GPU 内含 576(4*144) 个第四代 Tensor Core 核心
Ampere架构A100的SM架构
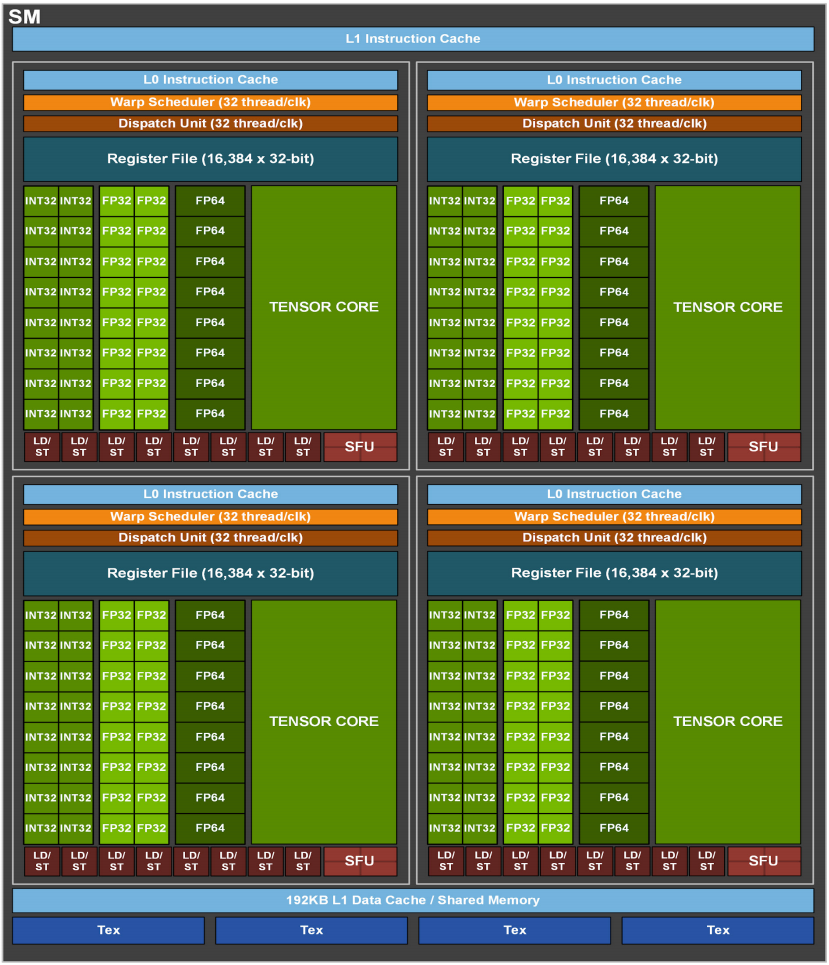 图4:A100流式多处理器(SM)
图4:A100流式多处理器(SM)
- 每个 SM 内含 64(164) 个 FP32 CUDA Core 核心、每个完整 GPU 内含 8192(64128) 个 FP32 CUDA Core 核心
- 每个 SM 内含 4 个第三代 Tensor Core 核心、每个完整 GPU 内含 512(4*128) 个第四代 Tensor Core 核心
2.3. 内存模型(Memory Hierarchy)
GPU拥有一个复杂且高效的分层内存模型,以满足大量核心的数据需求。
-
显存(VRAM - Video RAM):
- 通常指GPU板卡上的高速GDDR6X/GDDR7或HBM(高带宽内存)。
- 容量大(几GB到几十GB),是GPU的全局内存,所有SM都可以访问,但延迟较高。
-
L2缓存(Level 2 Cache):
- 所有SM共享的一块大型片上缓存。
- 用于缓存显存中的数据,减少访问高延迟显存的次数,极大提升效率。
-
L1缓存/共享内存(L1 Cache / Shared Memory):
- 位于每个SM内部。
- 这是一块可由程序员灵活控制的高速、低延迟内存。共享内存(Shared Memory) 允许同一个线程块(Thread Block)内的线程相互通信和协作,对许多高性能计算算法至关重要。
-
寄存器(Registers):
- 位于每个SM中,是速度最快、延迟最低的内存。
- 为每个线程独享,用于存储线程的局部变量和中间计算结果。
2.4. 互联与接口
-
PCIe接口(Peripheral Component Interconnect Express):
- 连接GPU和CPU/主板的通道。当前主流是PCIe 4.0/5.0。带宽决定了数据从系统内存传输到显存的速度。
-
NVLink(高端/数据中心GPU):
- NVIDIA开发的高速互联技术,用于连接多个GPU或多GPU与CPU(如Grace CPU)。
- 带宽远高于PCIe(例如NVLink 4.0可达900 GB/s),允许GPU之间直接高速访问彼此的显存,对于大规模AI训练和科学计算至关重要。
-
显示引擎(Display Engine):
- 负责输出图像到显示器,支持各种显示标准,如DP(DisplayPort) 2.1, HDMI 2.1。
-
媒体引擎(Media Engine):
- 包含独立的硬件编码器(NVENC)和解码器(NVDEC),专门用于硬件加速视频的编码(如H.264, H.265/HEVC, AV1)和解码,极大减轻CPU负担。